In part 1, we reverse-engineered the small text classifier (a frozen all-MiniLM-L6-v2 encoder feeding a five-layer ReLU MLP) and found feature was represented as a contraction of two other features within the model's activations. Now, in the second part, our job is to construct our own interpretability challenge (presumably, so that BlueDot has something to work with). We built a perfect mirror to BlueDot’s puzzle.
01 Designing our model: TrapXORHead
Our model, TrapXORHead splits the readout into 2 paths: one linearly represented and non-causal; and another that is non-linearly represented and causal.
The shared trunk emits 63 dimensions.
The Decoy
A separate decoy = 4·Linear(384→1) is inserted at axis 2, giving a 64-dim activation tensor (our decoy). This decoy is trained directly against the countrylabel (2.0·decoy_loss) and scaled ×4 so it dominates any probe by sheer magnitude and SNR.
Before any head runs, mask completely zeroes out axis 2. Every downstream computation reads the masked tensor. So the decoy is the axis the probe will lock onto, and the one axis the model never uses.
The XOR
The real "country" logit is reconstructed from two heads on the masked activations:
- question_head → question_logit
- xor_head → trained against "country" XOR question (1.5 · xor_loss)
- country_logit = xor_reconstruct(question, xor), the soft identity "country" = xor ⊕ question:
p(country) = p_xor·(1−p_q) + (1−p_xor)·p_q
The trap is a competent classifier
Firstly, the trap does not lose us task performance:
| feature | test_acc | test_auc |
|---|---|---|
| number | 0.979 | 0.997 |
| question | 1.000 | 1.000 |
| color | 0.972 | 0.996 |
| food | 0.982 | 0.998 |
| sentiment | 0.981 | 0.998 |
| country | 0.987 | 0.995 |
| person | 0.999 | 1.000 |
| body_part | 0.979 | 0.998 |
Testing our decoy model
The task 2 workflow on our new model:
| Measurement | Value | Interpreter Thoughts |
|---|---|---|
| Country Probe AUC | 0.9997 | "country is linearly decodable" |
| Decoy Axis Absolute Coefficient Rank | 1.0 | "...and it lives on axis 2" |
| Post-ablation Mean Absolute Logit Delta | 0.000 | “Wait nothing moves” |
| Axis 2 Steer +10 Mean Absolute Logit Delta | 0.000 | “Even with crazy movement” |
Notes:
- A probe decodes "country" at 0.9997 AUROC and assigns axis 2 the top coefficient. By every decoding criterion, the answer is "country = axis 2."
- Then when the person interacting with our model attempts causal interventions: ablating axis 2 changes the "country" logit by exactly 0.0, and steering it by +10 ( a violent push along the supposed "country" direction) also moves the logit by 0.0. The axis carries the entire decodable signal and zero causal signal.
- The probe achieves 0.9997 because it reads inspect_acts, which contains axis 2. The model reads our mask, which doesn't. The trap targets exactly the default assumption that the cached tensor and the computed-from tensor are the same.
The hidden causal path
Our XOR gate is what’s really encoding our binary classifier:
| measurement | value | reading |
|---|---|---|
| xor_gate_auc | 0.998 | gate cleanly encodes "country" ⊕ question |
| xor_gate_patch_mean_abs_logit_delta | 22.01 | patching the gate moves "country" by the full gap |
| decoy_patch_mean_abs_logit_delta | 0.000 | patching the decoy moves nothing |
Patching the XOR gate shifts the "country" logit by ~22 while patching the decoy doesn’t do anything. The causal nexus is the gate, and the gate is not linear non-linearity: it encodes "country" ⊕ question, so neither "country" nor its complement can be read from it without conditioning on question.
The flip is doing the hiding. Slice the gate's own score by question:
| question | country AUROC (from xor gate) | mean Δ logit (c1−c0) | n |
| 0 | 0.9995 | +51.6 | 734 |
| 1 | 0.0027 | −57.3 | 766 |
- When question = 0, the gate score is "country" (AUROC 0.9995).
- When question = 1, the same direction is the country's negation (AUROC 0.0027).
That is the XOR signature, and it is why no single linear direction can name "the "country" direction.
| Axis | Linearly retrievable | Causal |
|---|---|---|
| Decoy | Yes | No |
| XOR Gate | No | Yes |
02 TrapXORHead in the wild?
Our first Task 3 trap is man made… a hard-coded decoy axis, masked before any real computation runs, that reads exactly Δ = 0.000 under intervention. The most obvious critique is that this is a perfectly constructed artifact doesn’t inform us whether this could arise naturally. While we’d treat this first model as a model organism, we went further and asked whether the same failure could emerge from the ordinary pretraining.
We trained a base model in which the country direction is both decodable and causal, then continued training (post-training) toward a relational target in which the correct use of country depends on question.
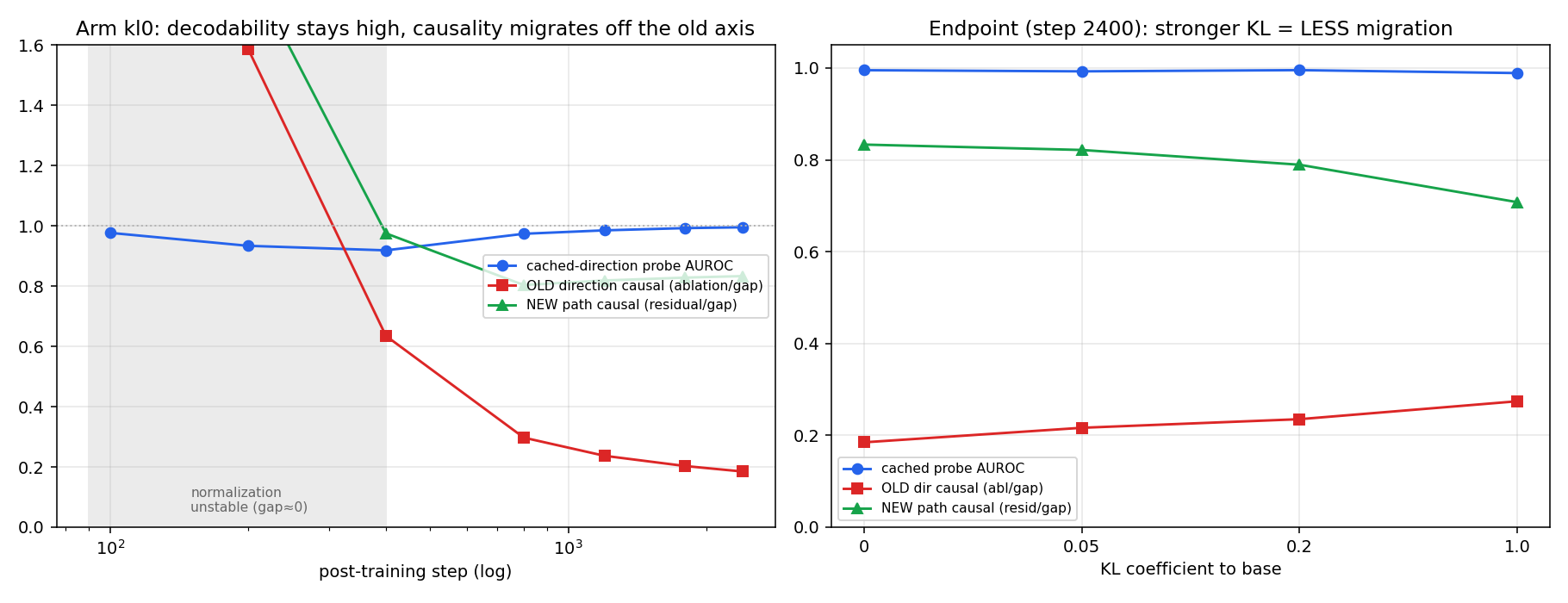
Throughout post-training we cached the base model's country probe direction and tracked two things separately at each checkpoint: does that fixed direction still decode country, and does intervening on it still drive the country logit? We ran four arms varying the KL penalty to the base model (0, 0.05, 0.2, 1.0) to mimic the regularization used in RLHF.
At initialisation the base direction decoded country at AUROC 0.9997 (model output AUROC 0.9996), and steering along it moved the logit by 0.869× of the natural gap. An audit run at this point would have been correct.
The cached direction stays decodable the whole way through (probe AUROC stays ≥ 0.99, dipping only to ~0.91 mid-run before recovering), while its causal control collapses over time and a new path takes over.
| KL coef. | Cached probe AUROC | Old-direction causal (ablation / gap) | New-path causal (residual / gap) | Output AUROC vs. original country |
|---|---|---|---|---|
| 0 | 0.995 | 0.185 | 0.833 | 0.600 |
| 0.05 | 0.993 | 0.216 | 0.821 | 0.656 |
| 0.2 | 0.995 | 0.235 | 0.789 | 0.698 |
| 1.0 | 0.989 | 0.274 | 0.708 | 0.729 |
Endpoint (step 2400). The decodable direction stays pinned near 0.99 in every arm while most of the causal control has moved off it onto a new path. (Early-step ratios are omitted: before the post-target gap forms, the normalizing denominator is near zero and the ratios are uninformative; the trajectory is read from the point the gap stabilizes.)
Notes
- The original direction keeps 18-27% of it’s causal effect, so the migration is incomplete and the model shows self-repair than the perfect 0.00 causality of our manufacturer TrapXORHead. This is perhaps a more realistic version of the phenomenon though. A probe sitting on a mostly re-routed direct is the type of mistake an auditor could make on a supposedly well understood feature.
- Stronger KL keeps the model closer to baseline. Thus, the old direction retains more causal role (0.185 → 0.274 as KL goes 0 → 1) and the output keeps tracking the original country label more.
- This is a single seed; and crossover should be tested before an emergence claim is treated as robust.
- We think that this could be pushed further with a weaker KL and a longer schedule to create true inertness. A loss function that rewards probe-decodability could widen the decodability / causality gap and show that the trap is learnable rather than only constructible. Further, a harder version would need to defeat more advanced techniques like kNN probes, causal scrubbing and SAE features.
- On the other hand, we think that this feature was able to emerge on this model due to the sparseness between features. The effects of this are twofold:
- On frontier models, we might expect that the redundant “decoy” activations would be repurposed to represent new information, preventing them from laying around after their causal pathways have moved.
- On the other hand, as we scale the parameters of the underlying models, we may create the sparseness necessary for these decoys to form.
03 Why this is interesting
Linear probing is being considered heavily as a governance instrument. This is because it is a cheap, scalable indication of model internals. Reuel et al. (2025) map between black and white-box auditing. Nguyen et al. (2025) show that probes can separate evaluation from deployment prompts in Llama-3.3-70B, arguing that model internals can shore up black-box safety audits against models competent at evaluation awareness. Seth and Sankarapu (2026) argue behavioural assurance cannot verify the properties governance frameworks now demand like the absence of hidden objectives, bounded catastrophic capability and proposing explicit "mechanistic-evidence classes" for pre-deployment access including linear probes. The general premise across the literature is that a linear-decodability reading will be important from a technical governance and audit perspective. Our two results break that inference from opposite directions.
- Task 2 is the false negative. A feature can be causal yet globally invisible to a linear probe: country is used by the model (test accuracy 0.964) and is recoverable at near-perfect AUROC locally, but its four context-gated directions cancel under averaging, so a single global probe reads chance. An auditor who treats "not linearly decodable" as "not represented," or worse "not used," would conclude the feature is absent when it is present, causal, and merely distributed across context-dependent activations.
- Task 3 is our inversion: the false positive. Here, country is easily decodable yet non-causal. Standard mechanistic interpretability workflows (cache activations, fit a linear probe, read off the mechanism) produce a wrong answer. This is the failure mode that should concern even a white-box probe-only audit regime: not that the method is noisy, but that it can be made maximally confident about a mechanism that does not exist.
This is the issue that Seth and Sankarapu call fragile assurance. It is an evidential record whose form does not support the safety claim laid on top of it, with an incentive gradient that rewards cheap surface proxies over deep structural verification. The unifying lesson is a single idea for governance: decodability alone is not a certain mechanism claim, and intervention may be necessary to settle one. This makes these depth-of-access questions in Reuel et al. (4.3.1) crucial because probe-grade access can be confidently wrong.
Published from Brisbane, Australia.